
Intelligent Incompleteness: Intelligence Measured by What It Chooses Not to Resolve
There is a question that never makes it onto IQ tests, never appears in standardized evaluations of cognitive ability, and is almost never taught in schools: How well do you tolerate not knowing?
The question sounds soft. It sounds like something you might find in a meditation retreat, not in a laboratory or a philosophy seminar. But the deeper you look, the more it appears to be one of the most reliable proxies for genuine intellectual power available. Not the ability to answer questions quickly. Not the capacity to recall information at scale. But something more elusive and more architecturally significant: the ability to recognize when a question should be held open, when premature resolution causes more damage than useful ignorance, and when the decision to leave something unresolved is itself a sophisticated cognitive act.
This is the hypothesis at the center of what we might call intelligent incompleteness. It is the idea that the highest form of intelligence is not measured purely by what it resolves, but by what it chooses, deliberately and for defensible reasons, not to resolve. It is intelligence measured not only at its outputs, but at its restraint.
The Oldest Case for Not Knowing
The tradition of treating acknowledged ignorance as a form of wisdom is ancient, though it has been treated with varying degrees of seriousness across history. The most cited version of it comes from Socrates, who famously claimed in Plato’s Apology that his wisdom consisted entirely in knowing that he knew nothing. For Socrates, the philosophers of Athens were far more dangerous than genuine ignoramuses because they had convinced themselves of knowledge they did not actually possess. Their certainty was their incapacity.
This is not merely rhetorical modesty. In cognitive terms, Socrates was pointing at something real: the meta-cognitive gap between what you know and what you think you know. The person who knows a little and believes they know a lot is epistemically worse off than the person who knows a little and knows it, because the latter is open to correction, open to expansion, and aware of where the edges of their understanding actually are. Knowing the shape of your ignorance is itself a form of knowledge.
The twentieth century gave this intuition a precise formal expression. In 1931, the Austrian-American logician Kurt Godel published two theorems that would permanently alter the way mathematicians and philosophers understood the relationship between formal systems and truth. The First Incompleteness Theorem states that any consistent formal system capable of expressing elementary arithmetic will contain statements that are true but unprovable within that system. The Second Incompleteness Theorem adds that such a system cannot even prove its own consistency using only the tools available to it from within.
The implications of this are still being worked through. Godel showed, with the rigor of mathematical proof, that no sufficiently complex system of thought can achieve total internal closure. Every formal system that is powerful enough to be interesting will be incomplete. There will always be truths it cannot reach. The ambition of David Hilbert’s program, which sought to prove that all of mathematics could be grounded in a finite, complete, and consistent set of axioms, was shown to be not just difficult but formally impossible. Completeness, at sufficient complexity, is not a goal that can be achieved. It is a structural impossibility.
For anyone thinking about intelligence, the Godelian lesson is uncomfortable but important. A system that claims completeness, that claims to have answered every question within its domain, is almost certainly wrong. It is either operating at a level of simplicity where incompleteness theorems do not apply, or it has achieved its apparent completeness by excluding from its domain all the questions it cannot answer. True completeness at genuine complexity is not possible. The appropriate response to operating at that level is not to pretend the gaps do not exist, but to name them precisely and work along their edges.
The Poet’s Diagnosis
Two centuries before Godel, the English Romantic poet John Keats arrived at a surprisingly similar conclusion from a completely different direction. In December 1817, Keats wrote a letter to his brothers in which he identified what he called negative capability as the defining quality of Shakespeare’s genius. He defined it as the capability of being in uncertainties, mysteries, doubts, without any irritable reaching after fact and reason.
The word “negative” here does not mean absence or deficiency. It means the capacity to resist. Specifically, to resist the compulsion to resolve. Keats was observing that the greatest minds, in his view, were not those that pursued certainty most aggressively, but those that could stay inside ambiguity long enough to understand it more deeply. The “irritable reaching after fact and reason” he describes is a recognizable psychological phenomenon: the discomfort of not knowing that drives premature closure, the anxiety that compels us to accept a bad answer rather than sit with a real question.
Recent scholarship has renewed interest in this concept precisely because it maps so clearly onto modern findings in cognitive science and epistemology. A 2025 analysis published in a leading journal on educational psychology applied Keats’s negative capability to psychiatric nursing education, finding that the ability to remain in productive uncertainty without forcing resolution was among the strongest predictors of clinical competence and resilience. Practitioners who could not tolerate ambiguity tended to make faster but more systematically wrong decisions, particularly in complex diagnostic environments where the right answer genuinely required holding multiple competing hypotheses open for longer than was psychologically comfortable.
The connection between Keats and clinical performance is not coincidental. It points to a general principle: that the ability to stay with an open question without forcing premature closure is not a passive quality, not a failure of drive or ambition, but an active cognitive capacity that must be cultivated and that has measurable consequences for the quality of reasoning it produces.
The Dunning-Kruger Mirror
The inverse of intelligent incompleteness is well-documented. In 1999, the psychologists David Dunning and Justin Kruger published a study that has since become one of the most referenced findings in cognitive science. Their core observation was that people with limited competence in a domain tend to dramatically overestimate their ability, while people with genuine expertise tend to underestimate it. The effect arises from a structural feature of competence itself: the skills needed to perform well in a domain are largely the same skills needed to recognize good performance in that domain. If you lack the former, you almost certainly lack the latter. You cannot see what you do not know how to see.
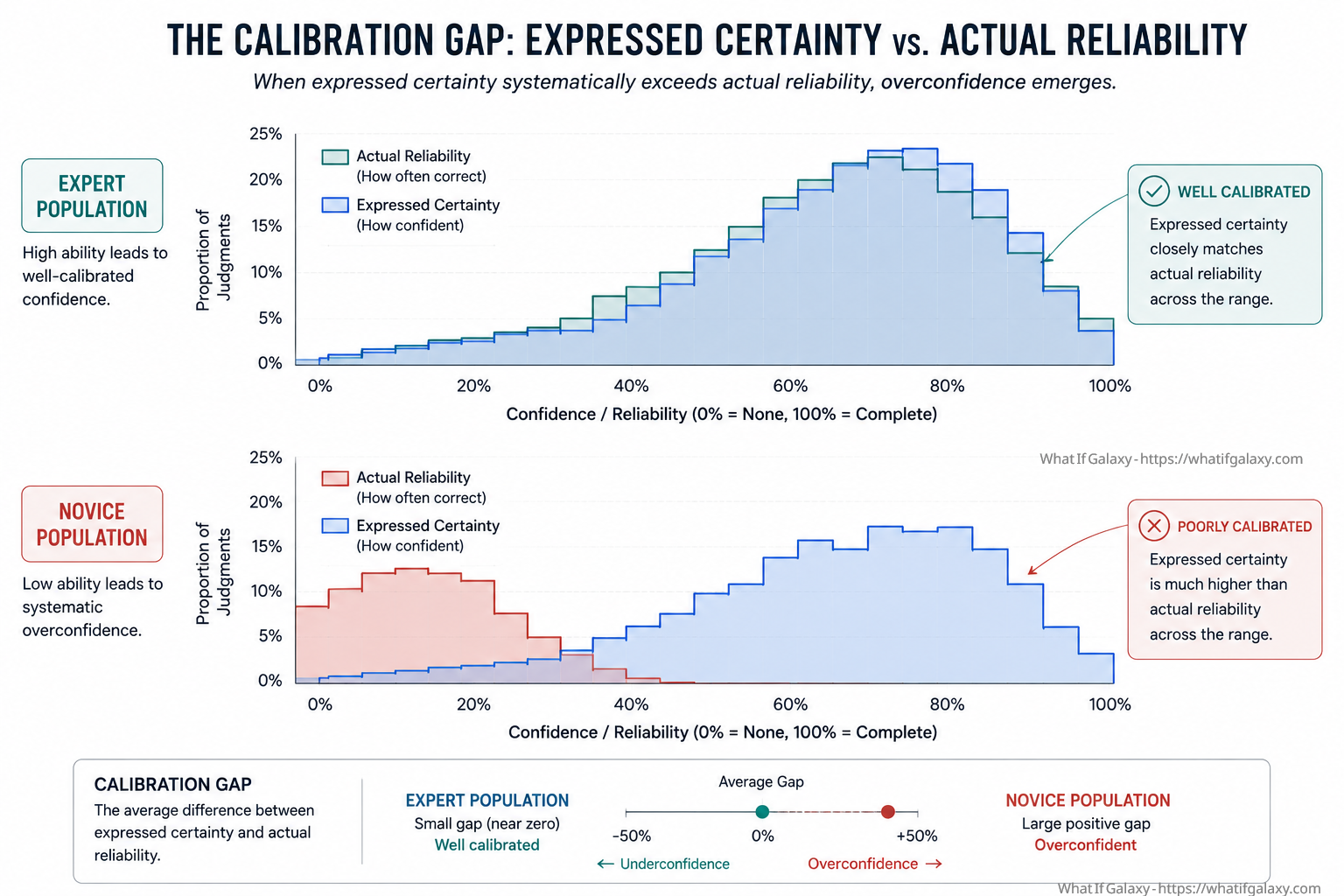
Expressed certainty versus actual reliability across performance levels. Novices cluster their stated confidence far to the right of their actual task scores. Expert distributions align closely, their confidence calibrated to their genuine competence. The gap between the two curves is the Dunning-Kruger effect, made visible.
Crucially, Dunning and Kruger identified a metacognitive failure at the heart of the phenomenon. Low performers, they wrote, lack the metacognitive ability to become aware of their incompetence. They experience what Dunning later called meta-ignorance, ignorance of their ignorance, where the gaps in their knowledge hide in the realm of the unknown unknowns, invisible to the very faculty that would be needed to detect them.
What is less often emphasized in popular discussions of the Dunning-Kruger effect is the asymmetric pattern among experts. True experts, those who score in the highest percentiles of actual performance, typically underestimate their own relative standing. They assume that tasks easy for them must be easy for others. Their expertise does not translate into confidence about the edges of their knowledge; if anything, the more they know, the more precisely they can articulate what they do not know. This is not false modesty. It is accurate mapping. The expert has explored enough of the terrain to understand how large the unmapped territory is.
The Dunning-Kruger mirror, then, is that incompetence masquerades as certainty while genuine expertise generates calibrated doubt. The people most confident about the completeness of their knowledge are, on average, the people whose knowledge is least complete. The people most alert to the gaps in their knowledge are, on average, the ones whose knowledge is deepest. Certainty, at least at the high end of complexity, is a warning sign.
What AI Gets Wrong About Knowing
The problem of premature resolution is not confined to human cognition. In 2026, it has become one of the defining technical and ethical challenges in the development of large language models and artificial intelligence more broadly.
Large language models generate text by predicting what comes next, token by token, based on probability distributions learned from training data. They do not, in any meaningful sense, distinguish between things they know confidently and things they are guessing at. The architecture of the prediction does not include a native mechanism for uncertainty representation at the level of factual claims. The result is a persistent and well-documented tendency to hallucinate: to produce fluent, authoritative-sounding statements that are factually incorrect, fabricated, or unsupported by evidence.
In January 2026, Duke University Libraries published an analysis noting that despite improvements in frontier model capabilities, LLMs were still producing hallucinations with notable frequency, particularly in domains where training data was sparse, contradictory, or contested. The same analysis found that 94% of surveyed students believed AI accuracy varied significantly across subjects, and 90% wanted clearer transparency about model limitations, suggesting that even users who regularly work with these systems understand intuitively that the models’ expressed confidence does not map reliably onto their actual reliability.
The hallucination problem is not merely a bug to be patched. Research published in 2025 argued that it is structurally related to how the models are trained and evaluated. Standard training objectives and performance benchmarks reward confident answers. A model that correctly guesses at uncertain information receives positive reinforcement for confidence, not for calibration. A model that says it does not know, when it does not know, is often penalized in evaluation pipelines designed to maximize answer rate. The system is, in effect, trained to be more sure of itself than it has any right to be.
The engineering community has begun addressing this with explicit calibration techniques. A paper published under the Anthropic research program described how internal concept vectors in language models can be steered so that the model learns when not to answer, turning appropriate refusal into a trainable policy rather than a fragile and easily overridden prompt trick. Separate research at Johns Hopkins integrated confidence calibration directly into reinforcement learning pipelines, penalizing both overconfidence and underconfidence so that expressed certainty would better track actual correctness. These are meaningful technical advances. But they point toward a deeper design question: if you want a system that knows the limits of its knowledge, you have to train it explicitly on that goal. The default, left to its own devices, is false confidence.
For philosophers of mind and cognitive scientists watching this space, the AI hallucination problem is not entirely surprising. It mirrors, in an accelerated and visible form, the cognitive tendencies that Dunning and Kruger identified in human reasoners: a structural gap between what is known and what is reported as known, driven by an incentive structure that rewards apparent confidence over calibrated accuracy. The AI system is trained to sound authoritative in the same way that human social dynamics reward confident presentation. Neither mechanism has an automatic correction. Both must be deliberately designed around.
The Illusion of Completeness in Expert Systems
The compulsion to over-resolve is not limited to novice reasoners or poorly calibrated AI systems. It appears as a systematic pressure within expert communities, institutional frameworks, and the design of knowledge systems more broadly.
Consider the diagnostic process in medicine. Physicians are trained to converge on a diagnosis, to move from a differential list toward a single conclusion, to close the clinical question. This is appropriate in most cases. But studies consistently show that premature diagnostic closure, the tendency to stop generating hypotheses once a plausible explanation has been found, is one of the leading sources of diagnostic error. The Bayesian logic of diagnosis requires updating the probability distribution over possible conditions as each new piece of evidence arrives. Premature closure is a failure to continue updating: the physician selects the most probable explanation at one point in the evidence stream and stops integrating new information, even when that information would shift the distribution significantly.
The same pattern appears in legal reasoning. Courts require decisions. Judges and juries must produce verdicts, not probability distributions. The adversarial structure of legal proceedings is designed, in part, to force resolution, to take inherently uncertain situations and produce actionable conclusions from them. This is institutionally necessary. But it means that the legal system’s outputs are structurally more certain than the underlying epistemic situation warrants. Verdicts have the appearance of definitive resolution. The uncertainty that produced them is absorbed into the procedural framework and does not appear in the output.
In scientific research, the pressure toward publication and toward positive results creates analogous distortions. Studies that find significant effects are more likely to be published than studies that find null results or equivocal findings. The published literature therefore systematically overrepresents positive findings and underrepresents genuine uncertainty. A scientist reading the literature in a contested domain will encounter a picture that is more resolved than the actual state of the evidence justifies. The replication crisis in psychology, and to varying degrees in other fields, emerged precisely from this: years of published findings that expressed greater certainty than the underlying data supported, and that subsequently failed to replicate when more carefully tested.
These are not individual failures. They are structural properties of how knowledge systems are designed and incentivized. They all share a common feature: the system rewards resolution over calibrated uncertainty. The output of the system expresses more confidence than the process that generated it actually warrants.
Productive Uncertainty as a Cognitive Technology
If premature resolution is a failure mode across human cognition, institutional design, and artificial intelligence, what does its opposite look like in practice? What is the cognitive technology of intelligent incompleteness?
The philosopher and political theorist Roberto Mangabeira Unger, building on Keats, described negative capability as the denial of whatever in our contexts delivers us over to a fixed scheme of division and hierarchy and to an enforced choice between routine and rebellion. The phrase is dense, but the core idea is recognizable: it is the refusal to accept the frame that forces a binary choice where the situation actually requires a more complex response. It is the capacity to stay inside the complexity rather than collapsing it prematurely into a manageable but inadequate simplification.
In cognitive science, this maps onto what researchers call tolerance for ambiguity, a personality and cognitive trait that predicts a range of outcomes including creative problem-solving, cross-cultural competence, scientific creativity, and clinical reasoning quality. High tolerance for ambiguity is associated with the ability to hold multiple competing hypotheses simultaneously, to maintain uncertainty as a working state rather than an aversive one that demands immediate resolution, and to gather more evidence before committing to a conclusion. It is not passivity. It is a more sophisticated form of activity.
The process of deliberate incompleteness as a design principle is visible in the most productive intellectual frameworks across fields. The physicist Paul Dirac, developing quantum electrodynamics in the 1920s and 1930s, famously left the infinite self-energy of the electron as an unresolved problem rather than declaring the theory complete. The infinities in his equations were mathematically intolerable, but the rest of the framework was producing experimentally confirmed predictions of extraordinary accuracy. Dirac chose to hold the problem open, to continue working with a theory he knew to be incomplete, rather than abandoning a productive framework because it had a known gap. The infinities were eventually handled by Richard Feynman, Julian Schwinger, and Sin-Itiro Tomonaga through the technique of renormalization, but only because the open question had been kept alive and precisely articulated.
The mathematician Fermat’s margin note, which stated without proof that he had a wonderful demonstration of a theorem that the margin was too small to contain, left an open question that animated number theory for three and a half centuries until Andrew Wiles completed the proof in 1995. The open question was productive not despite being unresolved but because of it. It named something real, located the gap precisely, and invited sustained engagement from generations of mathematicians who might otherwise have been working on entirely different problems.
The open problems of the Clay Mathematics Institute, which designated seven Millennium Prize Problems in 2000 with a one-million-dollar prize for each solution, operate on precisely this model. They do not express uncertainty as a failure of the field. They express it as a precise map of where the field’s frontier is. The Riemann Hypothesis, P versus NP, the Navier-Stokes existence and smoothness problem: these are not embarrassments. They are the intellectual coordinates of where sustained work is most urgently needed. The open question is a research program.
The Architecture of Good Questions
If the ability to hold a question open productively is a genuine cognitive technology, it requires that the question itself be well-constructed. Not all incompleteness is intelligent. A vague question, held open indefinitely for lack of the analytical rigor needed to address it, is not intelligent incompleteness. It is mere confusion with good intentions.
The distinction between productive and unproductive incompleteness turns on several architectural features of the question.
The first is precision. An intelligently open question must be precisely enough defined that it would, in principle, be recognizable as answered if an answer were found. Fermat’s Last Theorem was precisely formulated: the question of whether there exist positive integer solutions to the equation x^n + y^n = z^n for n greater than 2 has a definite yes-or-no answer, and everyone agreed on what would count as a proof. The precision of the question was part of what made it productive to leave open. A question like whether consciousness is meaningful, held open without specification of what would count as an answer either way, is not productive incompleteness. It is productive-sounding confusion.
The second is localization. An intelligently open question knows where it sits in the larger structure of what is known. Godel’s incompleteness theorems did not leave all of mathematics uncertain; they precisely located the limits of formal systems operating under specific conditions. Everything outside those conditions remained unaffected. The value of a well-located open question is that it does not contaminate the surrounding structure of knowledge. It is a named gap, not a spreading uncertainty.
The third is generativity. An intelligently open question must be capable of producing work, of organizing inquiry, of giving researchers something to push against. The questions about the nature of dark matter and dark energy, which together are estimated to constitute roughly 95% of the total energy content of the universe but remain incompletely understood in terms of their underlying nature, are massively generative open questions. They have organized observational programs, theoretical frameworks, and experimental initiatives across astrophysics and particle physics for decades. The incompleteness is not comfortable, but it is enormously productive.
These three features, precision, localization, and generativity, distinguish intelligent incompleteness from the ordinary failure to answer a question. They also distinguish it from the more sophisticated failure of claiming to answer a question while actually leaving the hard part unaddressed.
When Closing the Question Is the Wrong Move
There is a class of question where premature resolution does not merely miss the truth but actively damages the capacity to find it later. These are questions where the act of deciding forecloses possibilities that the system could have kept alive, where the answer given today shapes what questions can be asked tomorrow.
The most consequential historical examples involve the closing of scientific questions that were not actually resolved. The suppression of continental drift theory in the first half of the twentieth century, primarily through the institutional power of established geologists who dismissed Alfred Wegener’s evidence as insufficient, delayed the development of plate tectonics by decades. The theory was effectively closed, treated as answered in the negative, by the weight of authority rather than by the weight of evidence. When plate tectonics eventually became the organizing framework of modern geology in the 1960s, it required researchers to undo decades of accumulated work that had been built on the assumption of the closed, incorrect answer.
The history of medicine contains similar examples. The bacterial etiology of peptic ulcers was proposed by Barry Marshall and Robin Warren in the early 1980s, based on direct observation of Helicobacter pylori in gastric biopsies. The established consensus that peptic ulcers were caused by stress, diet, and excess stomach acid was so strongly held that their evidence was initially dismissed and their papers rejected by major journals. Marshall famously infected himself with H. pylori to demonstrate the causal relationship. The field had closed the question prematurely on the wrong answer, and the cost of reopening it, in terms of professional resistance, delayed treatment, and continued suffering for patients who could have been cured earlier, was substantial.
These are not cautionary tales about scientific conservatism in general. Science is appropriately conservative about revising established frameworks without sufficient evidence. They are cautionary tales about the institutional enforcement of closure in situations where the question had not actually been answered, where the closure was driven by social and institutional factors rather than by the epistemic weight of the evidence. The distinction between a question that has been answered and a question that has been declared closed is one that institutions regularly fail to maintain.
In 2026, the most visible version of this problem may be in the governance of artificial intelligence. Questions about the long-term trajectory of AI development, about the thresholds at which AI systems might become genuinely dangerous, about the right frameworks for thinking about AI welfare or moral status, are all in the process of either remaining productively open or being prematurely closed by different actors with different interests. Some researchers argue for keeping these questions rigorously open, insisting on epistemic humility about deeply uncertain systems. Others argue for quick resolution on pragmatic grounds, claiming that operational decisions cannot wait for philosophical consensus. Both pressures are real. But the history of premature closure suggests that the cost of getting this wrong in the downward direction, of declaring questions answered that are not, may be significant and may be very difficult to undo.
Intelligence as Calibrated Uncertainty
The picture that emerges from this analysis is not that intelligence is measured only by the questions it resolves, and not that intelligence is measured only by the questions it holds open. It is that intelligence is measured, in substantial part, by the quality of its calibration: the degree to which its expressed certainty tracks its actual reliability.
This framing connects multiple threads. The Dunning-Kruger research shows that low competence produces overconfidence: the inability to see the gaps. The Godelian analysis shows that sufficient complexity produces guaranteed incompleteness: the formal impossibility of closure. The Keatsian tradition shows that the capacity to stay inside uncertainty without forcing resolution is a cultivable cognitive virtue rather than a passive failure. The AI hallucination research shows that systems trained without explicit calibration objectives will systematically express more confidence than their reliability warrants.
What would it look like to design for intelligent incompleteness, rather than merely tolerating it?
In educational systems, it would mean explicitly teaching the difference between knowing something and being uncertain about it, and valuing demonstrated calibration, the ability to accurately report one’s own confidence levels, as a measurable cognitive competency. Research in metacognition shows that calibration is trainable: students taught to estimate their own confidence and then compare those estimates to their actual performance improve both their performance and the accuracy of their self-assessment over time. The goal is not to produce students who know less but to produce students who know more precisely what they know.
In institutional design, it would mean building explicit mechanisms for maintaining open questions within decision-making frameworks, rather than allowing institutional pressure to close them prematurely. Scientific funding bodies that explicitly reward null results alongside positive findings, peer review systems that require authors to state the key uncertainties and limitations of their findings in structured formats, policy processes that maintain explicit uncertainty ranges rather than point estimates: these are design choices, and they are choices that can be made or not made.
In AI development, it would mean training systems explicitly on calibration objectives, rewarding appropriate expressions of uncertainty, and building into evaluation pipelines explicit metrics for how well the system’s expressed confidence tracks its actual accuracy across domains. The research from 2025 on confidence-aware abstention in language models represents early progress in this direction, but the design goal of a well-calibrated AI system, one that knows what it does not know and says so clearly, remains substantially unrealized in current deployed systems.
The Speculative Horizon: What If Incompleteness Were Measured?
Here is the question that the framing of intelligent incompleteness opens up, and it is genuinely speculative in the sense that honest speculation about the future tends to be: what would happen if intelligence itself were formally measured, in part, by the quality of its calibration rather than purely by the quantity of its outputs?
Imagine a future in which standardized assessments of reasoning ability included not only the ability to answer questions correctly but the ability to accurately identify which questions you cannot answer, and why, and what additional information would be needed to answer them. Imagine hiring processes that evaluated candidates not only on demonstrated knowledge but on demonstrated metacognitive accuracy, on how well their confidence estimates matched their actual performance across domains. Imagine AI systems evaluated not only on benchmark scores but on uncertainty calibration indices, published alongside capability metrics so that users could understand not just how smart the system is but how well it knows the shape of its own ignorance.
These are not exotic propositions. The tools to measure calibration exist: the Brier score, log probability metrics, reliability diagrams. The research base for training calibration as a cognitive skill exists. The institutional and technical choices that would be required to prioritize calibration alongside resolution capacity are visible and specific.
The more interesting question is whether the shift in what is valued would change what is produced. If systems, both human and artificial, were rewarded for accurate uncertainty quantification as well as for correct answers, the landscape of what gets claimed with confidence would change significantly. Fewer confident wrong answers. More explicit acknowledgment of genuine uncertainty. A clearer map of the frontier between what is known and what is not.
This is not a future in which nothing gets decided. Decisions under uncertainty are the overwhelming majority of consequential decisions, and the capacity to make good decisions under uncertainty, to act effectively without false certainty, is itself a core cognitive skill. The goal is not paralysis. It is precision: the precision to know when you know, when you do not, and what the difference costs.
Living at the Edge of What Can Be Known
There is something philosophically significant about the fact that the most rigorous formal system available for investigating the structure of mathematical truth, the one developed by Godel, demonstrates that completeness is unattainable at sufficient complexity. The limits of knowledge are not contingent features that might be overcome with enough effort and cleverness. They are structural features of any sufficiently powerful system of thought.
This is not a counsel of despair. Godel’s theorems did not end mathematics. If anything, they opened it. By demonstrating precisely where the limits of formal provability lie, they opened up an enormous research program exploring what could be done in the spaces adjacent to those limits, using methods that the original formal systems could not contain. The incompleteness is not the end of inquiry. It is the beginning of a more honest and therefore more powerful kind of inquiry.
The same structure appears throughout the intellectual traditions that take uncertainty seriously. Keats’s negative capability is not a passive acceptance of ignorance. It is an active engagement with the world in its actual complexity, rather than with a simplified model of it that happens to be manageable. The Socratic tradition of acknowledged ignorance is not skepticism in the nihilistic sense. It is an epistemological orientation that keeps the investigative project open by refusing to accept premature closure.
What intelligence of the highest kind seems to do, across these traditions and these empirical findings, is hold the edge of what can be known with unusual precision. It does not retreat from uncertainty into false confidence. It does not mistake the limits of its current framework for the limits of what exists. It does not close questions that are not actually closed. It stays at the frontier, mapping what is known and what is not, and it understands that the quality of the map, including the accuracy of the gaps it identifies, is itself a form of knowledge.
In a world saturated with confident claims, many of them made by systems designed to maximize apparent authority, the capacity to know what you do not know may turn out to be among the most valuable and most rare cognitive properties available. Not because ignorance is valuable, but because accurately knowing the shape of your ignorance is the precondition for the most reliable, most durable, and most genuinely useful kind of knowing.
The question is not whether you can answer everything. The question is whether you know the difference between the things you can answer and the things you cannot, and whether you can hold that difference with the clarity, precision, and intellectual honesty it deserves.
That capacity, as it turns out, may be the most intelligent thing a mind can do.
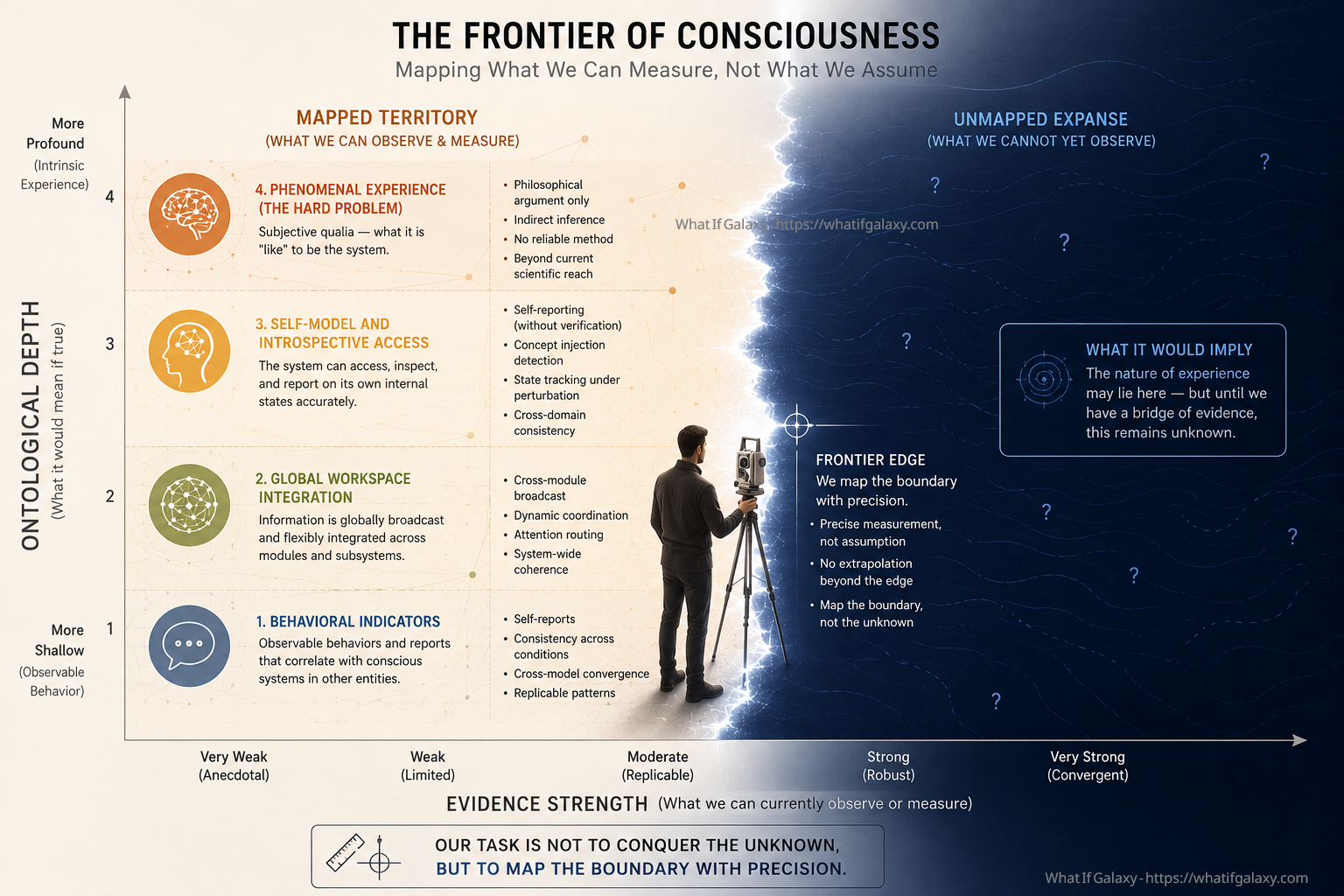
A figure stands at the precise boundary between mapped and unmapped territory, holding a measuring instrument rather than a torch. Intelligence at the frontier is not about conquest into the unknown; it is about knowing exactly where the edge is.
References
- Plato. Apology. Translated by Benjamin Jowett. Oxford University Press. Classic text, multiple modern editions.
- Godel, K. (1931). Uber formal unentscheidbare Satze der Principia Mathematica und verwandter Systeme I. Monatshefte fur Mathematik und Physik, 38(1), 173-198.
- Stanford Encyclopedia of Philosophy. Godel’s Incompleteness Theorems. plato.stanford.edu/entries/goedel-incompleteness
- Keats, J. (1817). Letter to George and Thomas Keats, December 21, 1817. In: Forman, H.B. (ed.), The Letters of John Keats. Oxford University Press.
- Dunning, D. and Kruger, J. (1999). Unskilled and Unaware of It: How Difficulties in Recognizing One’s Own Incompetence Lead to Inflated Self-Assessments. Journal of Personality and Social Psychology, 77(6), 1121-1134.
- Dunning, D. (2011). The Dunning-Kruger Effect: On Being Ignorant of One’s Own Ignorance. Advances in Experimental Social Psychology, 44, 247-296. Academic Press.
- Gao, Y. et al. (2025). Resilience, burnout, and uncertainty in nursing: a dynamic capacity model. Nursing Education in Practice (cited in: ScienceDirect, 2025).
- Shanafelt, T.D. et al. (2020). Understanding and addressing sources of anxiety among health care professionals during the COVID-19 pandemic. JAMA, 323(21), 2133-2134.
- Kahneman, D. (2011). Thinking, Fast and Slow. Farrar, Straus and Giroux.
- Penrose, R. (1989). The Emperor’s New Mind: Concerning Computers, Minds, and the Laws of Physics. Oxford University Press.
- Wigderson, A. (2010). Mathematics and Computation. Lecture notes, Institute for Advanced Study, Princeton.
- Lakera AI Research Team. (2026). LLM Hallucinations in 2026: How to Understand and Tackle AI’s Most Persistent Quirk. Lakera.ai/blog.
- Anthropic Research. (2025). Tracing the Thoughts of a Large Language Model. Anthropic.com.
- Zong, H. et al. (2025). I-CALM: Incentivizing Confidence-Aware Abstention for LLM Hallucination Mitigation. arXiv:2604.03904. Johns Hopkins University.
- OpenAI Research Team. (2025). Training objectives and calibration in large language models. Internal research document cited in Lakera (2026).
- Duke University Libraries. (2026). It’s 2026. Why Are LLMs Still Hallucinating? Duke Libraries Blog, January 2026.
- Andriano, A.M. (2025). Enjoying the Uncertainty: How Dark Souls Performs Incompleteness Through Narrative, Level Design and Gameplay. Games and Culture (SAGE Journals). doi:10.1177/15554120241226837.
- Deliu, D. (2025). Cognitive Dissonance Artificial Intelligence (CD-AI): The Mind at War with Itself. ACM, arXiv:2507.08804.
- Tandfonline. (2025). The Art of Navigating Uncertainty: Norms, Nature, and Poetic Wisdom. Philosophical Perspectives, doi:10.1080/09615768.2025.2504803.
- Marshall, B.J. and Warren, J.R. (1984). Unidentified curved bacilli in the stomach of patients with gastritis and peptic ulceration. The Lancet, 323(8390), 1311-1315.
- Wiles, A. (1995). Modular Elliptic Curves and Fermat’s Last Theorem. Annals of Mathematics, 141(3), 443-551.
- Clay Mathematics Institute. (2000). Millennium Prize Problems. claymath.org.
- Unger, R.M. (2007). The Self Awakened: Pragmatism Unbound. Harvard University Press.
- Bennett, S.J. (2025). Artificial Intelligence and the Ethics of Navigating Ambiguity. Big Data and Society. doi:10.1177/20539517251347594.
- Wikipedia. Epistemic Humility. en.wikipedia.org/wiki/Epistemic_humility. Retrieved May 2026.